Développer l’intelligence artificielle pour les dispositifs médicaux
L’utilisation de l’intelligence artificielle dans les dispositifs médicaux est en augmentation. Bien qu’il n’y ait pas encore de directive ou de cadre réglementaire spécifique, les décisions en matière d’IA doivent toujours être compréhensibles et vérifiables pour assurer la sécurité des patients. TÜV SÜD partage des aspects clés de l’intelligence artificielle dans l’industrie des technologies médicales.
Début janvier 2020, l’Organisation mondiale de la santé (OMS) a publié des informations sur un cas particulier de maladie pseudo-grippale à Wuhan, en Chine. Pourtant, une entreprise canadienne spécialisée dans la surveillance basée sur l’intelligence artificielle (IA) de la propagation des maladies infectieuses avait déjà averti ses clients du risque d’épidémie en Chine dès décembre 2019.1 L’avertissement était dérivé d’analyses basées sur l’IA de reportages et d’articles sur des réseaux en ligne sur les maladies animales et végétales. L’accès aux données mondiales sur les billets d’avion a permis à l’IA de prévoir correctement la propagation du virus dans les jours qui ont suivi son apparition.
Sommaire
- 1 Absence de cadre réglementaire
- 2 Tester les données d’entraînement de l’IA et définir la portée
- 3 Exemple : Identification de l’arthrose du genou
- 4 AI–Attention au problème de la boîte noire
- 5 Qualité des données
- 6 Conseils gratuits pour les développeurs et les fabricants
- 7 Liste de contrôle pour les dispositifs médicaux avec IA
- 8 Référence
Absence de cadre réglementaire
L’exemple révèle les capacités de l’IA et de l’apprentissage automatique (ML). Tous deux sont également utilisés dans un nombre croissant de dispositifs médicaux, par exemple sous forme de circuits intégrés. Malgré les risques également associés à l’utilisation de l’IA, les normes et réglementations communes n’incluent pas encore d’exigences spécifiques concernant ces technologies innovantes. Le règlement sur les dispositifs médicaux (MDR) de l’Union européenne, par exemple, ne définit que les exigences logicielles générales. Selon la réglementation, les logiciels doivent être développés et fabriqués conformément à l’état de l’art et conçus pour l’usage auquel ils sont destinés.
Cela implique que l’IA doit également garantir des performances prévisibles et reproductibles, ce qui nécessite à son tour un modèle d’IA vérifié et validé. Les exigences de validation et de vérification ont été décrites dans les normes logicielles IEC 62304 et IEC 82304-1. Cependant, il existe encore des différences fondamentales entre les logiciels conventionnels et l’intelligence artificielle avec l’apprentissage automatique. L’apprentissage automatique est basé sur l’utilisation de données pour entraîner un modèle, sans programmer explicitement les processus. Au fur et à mesure que l’entraînement progresse, le modèle est continuellement amélioré et optimisé grâce à des modifications des « hyperparamètres ».
Tester les données d’entraînement de l’IA et définir la portée
La qualité des données est cruciale pour les prévisions fournies par l’IA. Les problèmes fréquents incluent le biais, le surajustement ou le sous-ajustement du modèle et les erreurs d’étiquetage dans les modèles d’apprentissage automatique supervisés. Des tests approfondis révèlent certains de ces problèmes.
Il montre que les biais et les erreurs d’étiquetage sont souvent causés involontairement par des données d’apprentissage qui manquent de diversité. Prenons l’exemple d’un modèle d’IA qui est entraîné à reconnaître les pommes. Si les données utilisées pour entraîner le modèle comprennent principalement des pommes vertes de différentes formes et tailles, le modèle peut identifier une poire verte comme une pomme mais ne pas reconnaître une pomme rouge. Dans certaines circonstances, des caractéristiques communes accidentelles ou non intentionnelles d’aspects peuvent être considérées comme importantes par l’IA même si elles ne sont pas pertinentes. La répartition statistique des données doit être justifiée et correspondre à l’environnement réel. L’existence de deux jambes, par exemple, ne doit pas être appliquée comme un facteur critique pour la classification de l’IA en tant qu’être humain.
Les erreurs d’étiquetage sont également dues à la subjectivité (« gravité de la maladie ») ou à des identifiants inadaptés aux fins du modèle. L’étiquetage de gros volumes de données et la sélection d’identifiants appropriés est un processus long et coûteux. Dans certains cas, seule une très petite quantité de données sera traitée manuellement. Ces données sont utilisées pour entraîner l’IA. Par la suite, AI est chargé d’étiqueter les données restantes. Ce processus n’est pas toujours exempt d’erreurs, ce qui signifie que des erreurs seront reproduites.
Les facteurs clés de succès sont la qualité des données et le volume de données utilisées. Jusqu’à présent, les estimations empiriques de la quantité de données nécessaires à un algorithme sont rares. S’il est fondamentalement vrai que même un algorithme faible fonctionne bien si la qualité et le volume des données sont suffisamment importants, dans la plupart des cas, les capacités seront limitées par la disponibilité des données (étiquetées) et la puissance de calcul. La portée minimale des données requises dépend de la complexité du problème et de l’algorithme d’IA, les algorithmes non linéaires nécessitant généralement plus de données que les algorithmes linéaires.
Normalement, 70 à 80 % des données disponibles sont utilisées pour entraîner le modèle, tandis que le reste est utilisé pour la vérification de la prédiction. Les données utilisées pour la formation à l’IA doivent couvrir une bande passante maximale d’attributs.
Exemple : Identification de l’arthrose du genou
Selon l’IA boîte noire, l’un des deux patients représentés par les images suivantes développera une arthrose du genou dans les trois prochaines années. Ceci est invisible à l’œil humain et le diagnostic ne peut pas être vérifié. Un patient choisirait-il toujours de subir une intervention chirurgicale? (Les images suivantes ont été extraites de la publication suivante « Making Medical AI Trustworthy », Spectre IEEE.org, août 2018 [https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8423571], originaire de The Osteoarthritis Initiative [https://nda.nih.gov/]. Cet article reflète les points de vue de l’auteur et peut ne pas refléter les opinions ou les points de vue du NIH ou des chercheurs qui ont soumis les données originales à The Osteoarthritis Initiative.).
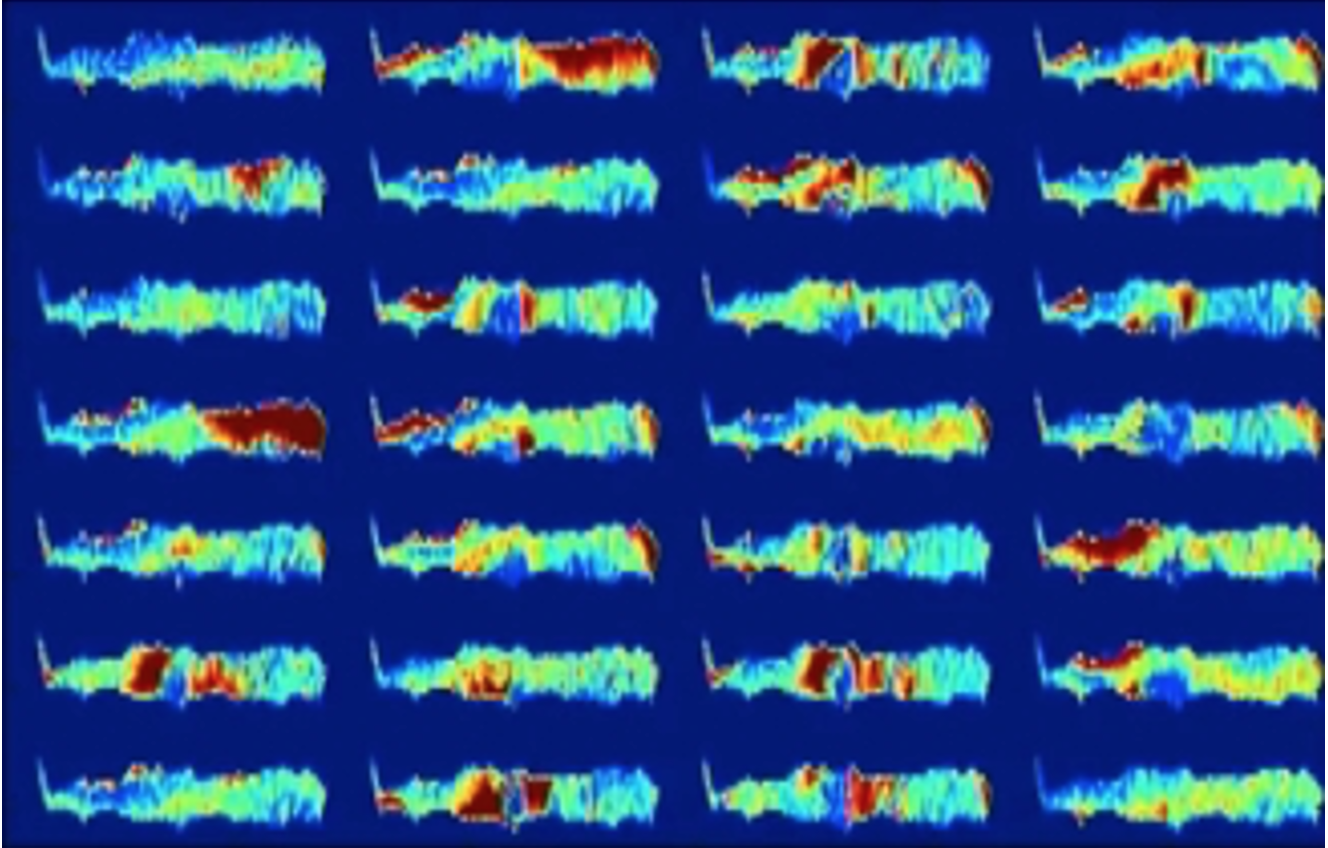
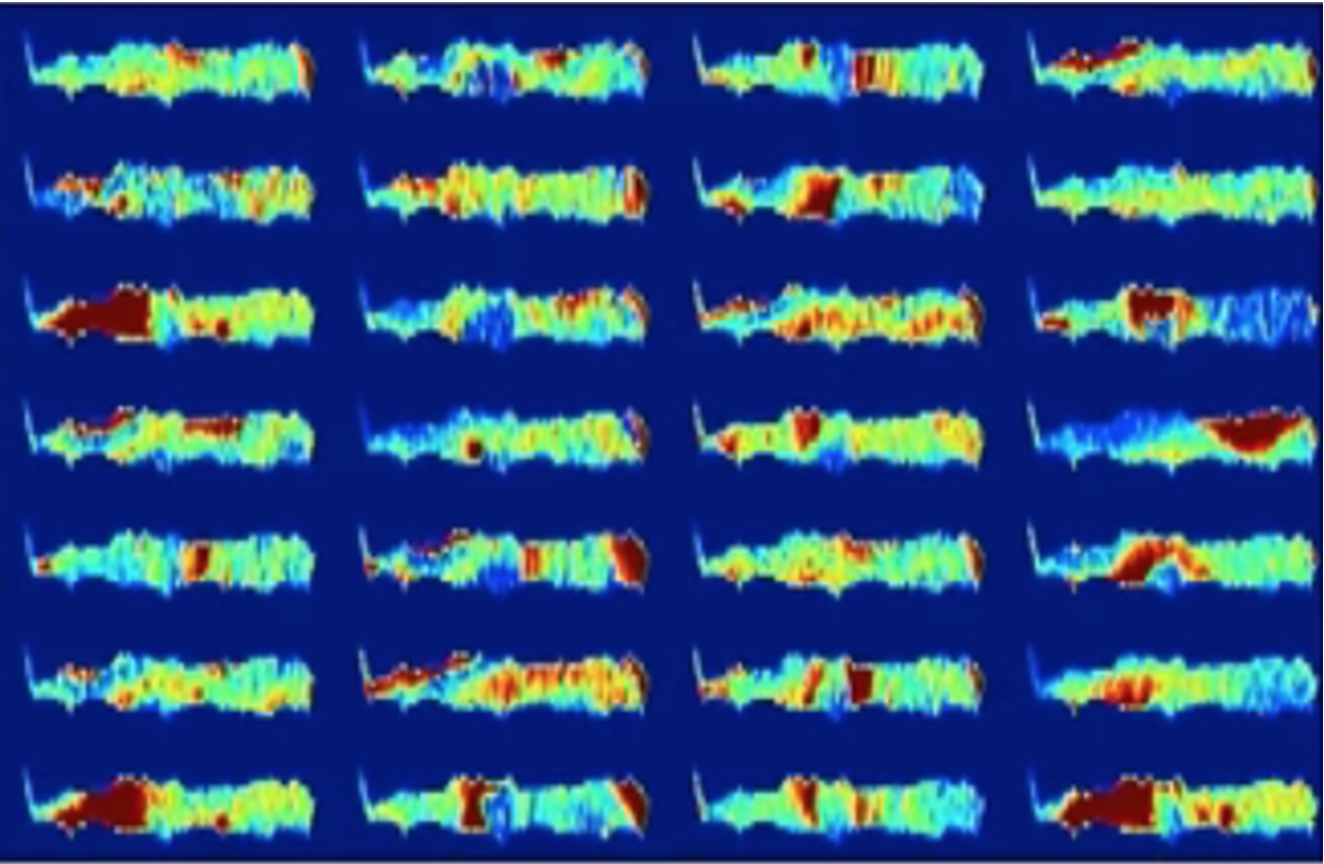
Ci-dessus : Figure 2. Ce patient souffrira d’arthrose dans les 3 prochaines années.
AI–Attention au problème de la boîte noire
La transparence de l’algorithme d’IA utilisé dans un dispositif médical est cliniquement pertinente. Comme les modèles d’IA ont des structures très alambiquées et non linéaires, ils fonctionnent souvent comme une « boîte noire », c’est-à-dire qu’il peut être très difficile, voire impossible, de comprendre comment ils prennent leurs décisions. Dans ce cas, par exemple, les experts ne peuvent plus déterminer quelle partie des données saisies dans le modèle (par exemple, des images diagnostiques) déclenche la décision prise par l’IA (par exemple, un tissu cancéreux détecté dans une image).
Les méthodes d’IA utilisées dans la reconstruction d’images MRT et CT se sont également avérées instables dans certains cas. Même des changements mineurs dans les images d’entrée peuvent conduire à des résultats complètement différents. L’une des raisons est que les algorithmes sont développés dans certains cas avec précision mais pas avec la stabilité à l’esprit.
Sans prévisions d’IA transparentes et explicables, la validité médicale d’une décision pourrait être mise en doute. Certaines erreurs actuelles de l’IA dans les applications précliniques augmentent encore ces doutes. Cependant, pour garantir une utilisation sûre chez les patients, les experts doivent être capables d’expliquer les décisions prises par l’IA. C’est la seule façon d’inspirer et de maintenir la confiance.
Les figures suivantes montrent les différences entre l’IA boîte noire et l’IA boîte blanche.
Ci-dessus : Figure 3. IA boîte noire.
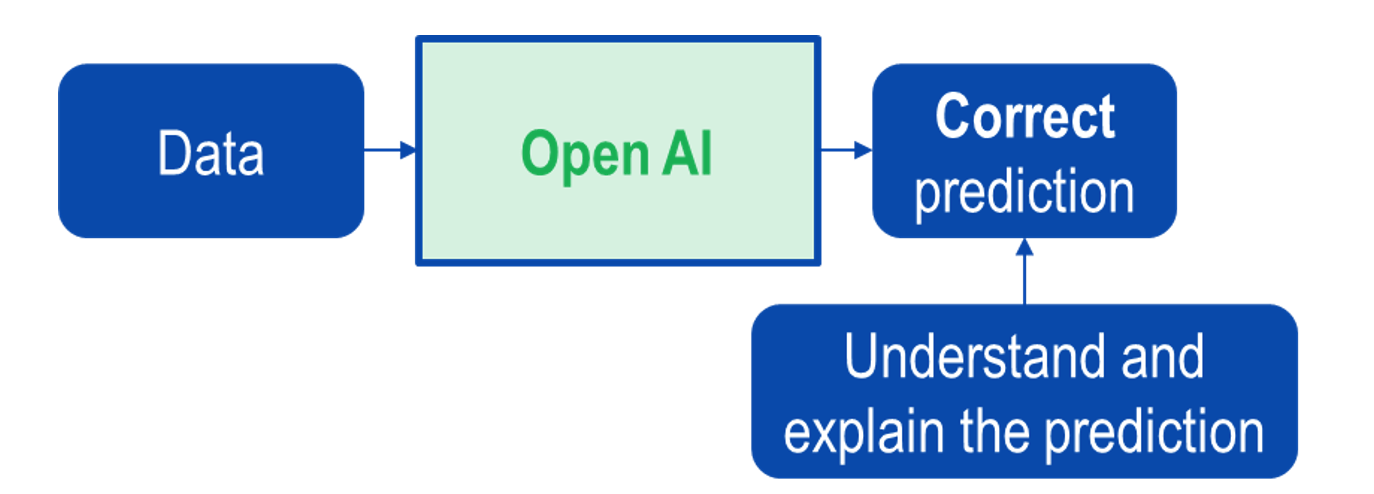
Ci-dessus : Figure 4. Ouverture de l’IA boîte noire.
Qualité des données
Les figures ci-dessous montrent les effets de la formation de l’IA à l’aide de données de faible qualité. Les exemples comprennent:
- Données biaisées (biais dans l’attribution des entrées à une catégorie de résultats).
- Sur-ajustement de données (voir Figure 6) Inclusion et pondération excessive de caractéristiques peu ou pas pertinentes.
- Sous-ajustement de données : le modèle ne représente pas l’exemple d’apprentissage avec une précision suffisante.
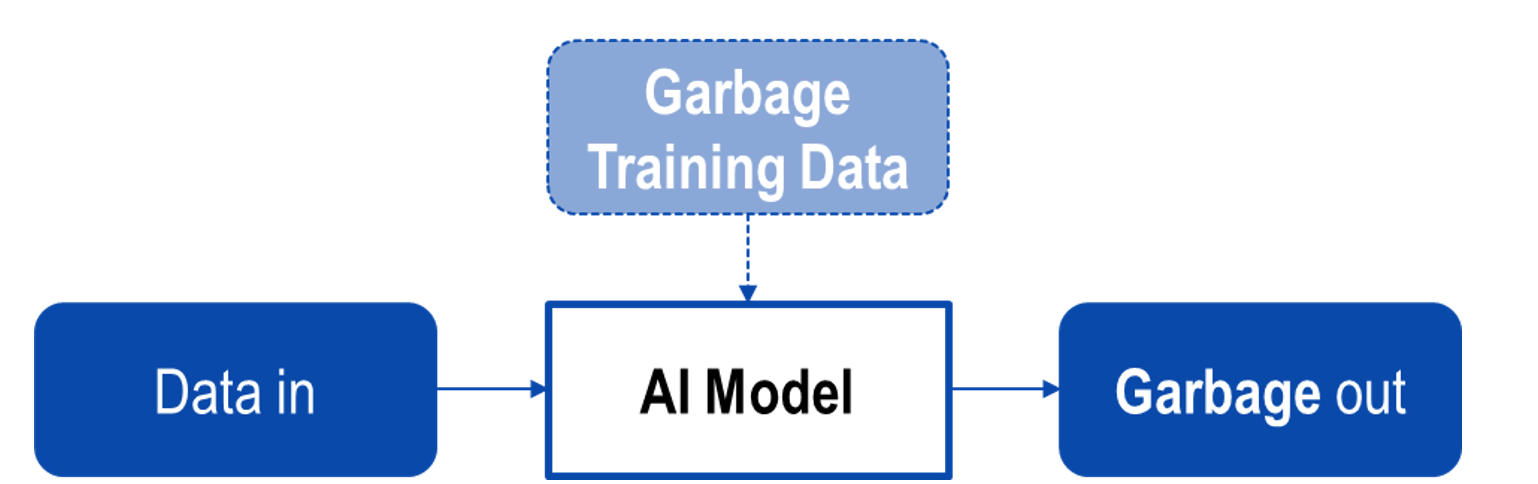 Ci-dessus : Figure 5. Effet de la formation utilisant des données de faible qualité.
Ci-dessus : Figure 5. Effet de la formation utilisant des données de faible qualité.
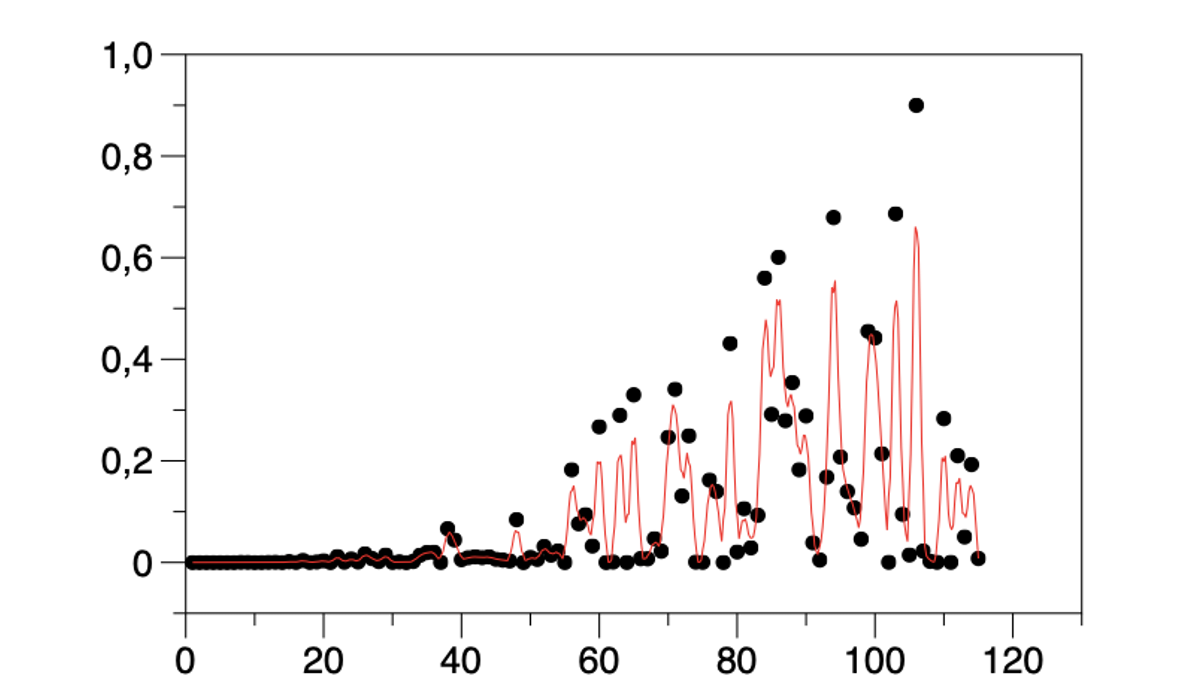
Ci-dessus : Figure 6. Sur-ajustement (ligne rouge) des données (points). Inclusion et pondération excessive de caractéristiques peu ou pas pertinentes.
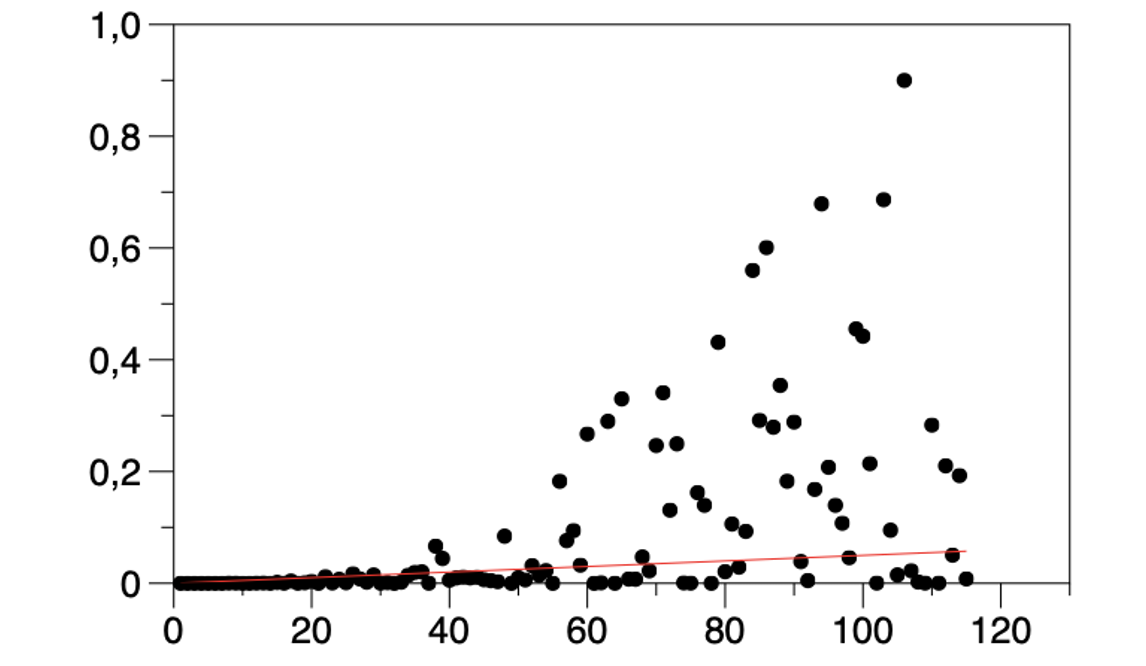
Ci-dessus : Figure 7. Sous-ajustement (ligne rouge) des données (points). Le modèle ne représente pas l’exemple d’apprentissage avec une précision suffisante.
Conseils gratuits pour les développeurs et les fabricants
Une liste de contrôle gratuite publiée par le Groupe d’intérêt des organismes notifiés en Allemagne (IG-NB) répertorie environ 150 exigences pour le développement et la surveillance post-commercialisation des dispositifs médicaux (voir l’encadré ci-dessous). Jusqu’à ce que des normes régissant la sécurité des dispositifs médicaux basés sur l’IA soient publiées, ce guide peut être utilisé pour minimiser les risques dans le cycle de vie de l’IA médicale. Cela facilite la mise sur le marché de nouvelles technologies dans un environnement par nature très réglementé.
Liste de contrôle pour les dispositifs médicaux avec IALa sécurité des dispositifs médicaux basés sur l’IA nécessite une approche centrée sur les processus dans toutes les phases du cycle de vie du produit. La liste de contrôle publiée par IG-NB couvre les trois domaines suivants : Exigences généralesLes exigences générales comprennent la certifiabilité de l’IA, les processus pertinents et les compétences requises pour le développement, ainsi qu’une documentation complète. Exigences pour le développement de produitsLes tâches comprennent l’identification des utilisateurs, la collecte des exigences logicielles et le développement et l’évaluation de modèles. Exigences pour les phases en avalAprès le développement, l’accent doit être mis sur la production, la distribution et l’installation. Ceci est aussi important qu’une surveillance post-commercialisation continue. La liste complète (en allemand uniquement) est disponible en téléchargement gratuit sur : www.ig-nb.de/dok_view?oid=795601 |
Référence
1. https://www.rnd.de/digital/coronavirus-warum-ein-algorithmus-zuerst-von-der-epidemie-wusste-JE32CSE745EW7CBU5ESLVE36ZE.html