DRAM – Plus important que vous ne le pensez pour atteindre la sécurité fonctionnelle automobile
Ne négligez pas l’importance de la fiabilité de la mémoire informatique dans les systèmes automobiles.
Une révolution dans l’industrie automobile est en cours et le matériel qui la pilote a un appétit pour la bande passante mémoire. Les fonctions de calcul hautes performances qui exécutent des algorithmes de perception, de planification et de contrôle dans les systèmes de conduite autonome nécessitent des sous-systèmes de mémoire plus rapides et de plus grande capacité. Par ailleurs, l’univers numérique du consommateur s’est étendu à l’automobile.
Les systèmes d’infodivertissement embarqués sont plus immersifs avec des fonctionnalités telles que la reconnaissance vocale et les écrans 4K. Les frontières entre l’infodivertissement et l’ADAS sont de plus en plus floues d’un point de vue matériel, car ces fonctions émergentes partagent des ressources, ce qui rend la sécurité fonctionnelle de ces systèmes primordiale.
Mais le rôle de la mémoire dans la réalisation des objectifs de sécurité fonctionnelle du système est essentiel et n’est pas bien compris par une grande partie de l’industrie. Il est important que ceux qui conçoivent des systèmes critiques pour la sécurité comprennent les modes de défaillance associés à la mémoire dynamique à accès aléatoire ou DRAM, ce que la DRAM offre en matière de couverture de diagnostic et comment atteindre les objectifs de sécurité du système avec la technologie de mémoire choisie.
Il est nécessaire d’avoir une compréhension de haut niveau de la façon dont les composants utilisés dans les systèmes critiques pour la sécurité sont évalués pour la conformité à la norme ISO 26262 (Véhicules routiers – Sécurité fonctionnelle). Premièrement, qu’est-ce que la sécurité fonctionnelle ?
La sécurité fonctionnelle consiste à éviter les risques inutiles de blessures corporelles dus aux dangers causés par la défaillance des systèmes E/E pendant le fonctionnement de l’automobile. L’analyse du risque de panne est définie par deux catégories, les pannes matérielles systématiques et aléatoires. Bien que cet article se concentre principalement sur les défauts matériels aléatoires, il est bon de comprendre comment l’analyse systématique des défauts joue un rôle dans la sécurité fonctionnelle.
L’analyse systématique des défauts est centrée sur la tentative d’éviter les défauts. Des exemples de défauts systématiques sont les défauts qui se produisent lors de la spécification, de la conception, de la fabrication, etc. Ces types de défauts peuvent affecter l’ensemble d’un parc automobile. En adhérant à un processus certifié ISO 26262 lors de la conception et de la fabrication d’un appareil, un niveau acceptable de risque de défauts systématiques peut être atteint.
Les défauts matériels aléatoires sont inhérents aux produits semi-conducteurs et se produisent pendant le fonctionnement du système. Celles-ci sont généralement causées par un défaut physique d’un appareil, mais peuvent survenir à la suite d’autres facteurs. Pour la DRAM, l’usure, les contraintes thermiques, les défauts de boîtier et les erreurs logicielles dues au flux de neutrons sont tous des exemples de mécanismes qui provoquent des défauts matériels aléatoires. Pour atteindre des niveaux de risque acceptables, les concepteurs de systèmes automobiles doivent se concentrer sur la détection d’un défaut matériel aléatoire.
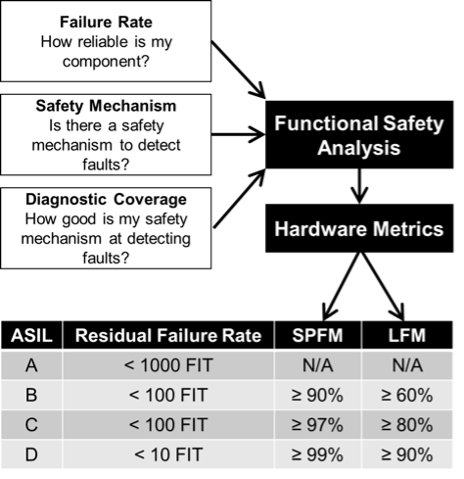
La figure 1 montre comment les métriques matérielles clés sont calculées via l’analyse de la sécurité fonctionnelle. Chaque niveau d’intégrité de la sécurité automobile (ASIL) a un ensemble différent d’exigences pour le taux de défaillance résiduel, la métrique de défaut unique (SPFM) et la métrique de défaut latent (LFM). Le SPFM est une métrique architecturale matérielle qui révèle si la couverture par les mécanismes de sécurité, pour prévenir le risque de défauts ponctuels dans l’architecture matérielle, est suffisante. De même, le LFM montre si la couverture par les dispositifs de sécurité, pour prévenir les risques de fautes latentes, est suffisante.
Le taux de défaillance résiduel est le taux d’erreurs non détectées et est exprimé en défaillances dans le temps (FIT), ce qui équivaut à des défaillances en 109 heures. L’exigence de taux de défaillance résiduel concerne l’ensemble du système et, généralement, le sous-système DRAM serait budgétisé à 4 % du total. Le budget DRAM FIT résultant serait de 4 pour l’ASIL B et de 0,4 pour l’ASIL D. Comme vous pouvez l’imaginer, avec les mémoires haute capacité déployées dans les systèmes actuels, il est difficile de répondre à ces exigences FIT.
La base de l’analyse de sécurité DRAM est l’analyse des modes de défaillance, des effets et du diagnostic (FMEDA). Il s’agit d’une approche ascendante pour décomposer tous les blocs fonctionnels DRAM et déterminer les mécanismes de défaillance possibles et les modes de défaillance qui en résultent. En utilisant les informations de la FMEDA, le système peut déterminer les meilleurs moyens de fournir la couverture de diagnostic requise par la norme ISO 26262.
Traditionnellement, la détection et la correction d’erreurs de la mémoire DRAM étaient axées sur les erreurs sur un seul bit (SBE), en d’autres termes, les SBE sont corrigées par le circuit de correction d’erreurs (ECC). En réalité, il existe d’autres façons dont la DRAM peut échouer qui nécessitent une réflexion beaucoup plus approfondie sur la détection et la correction des erreurs, en particulier dans un environnement de sécurité fonctionnelle. La figure 2 montre un schéma fonctionnel de haut niveau d’une DRAM moderne.
Vous pouvez voir qu’il existe de nombreux blocs de logique qui composent la périphérie de l’appareil, sans parler du réseau de distribution d’énergie. Le diagramme n’est pas à l’échelle, car en pratique, le réseau Mbit constitue la majeure partie de la zone de silicium de la puce, mais il est destiné à montrer l’existence d’autres blocs qui doivent être pris en compte dans l’analyse de sécurité.
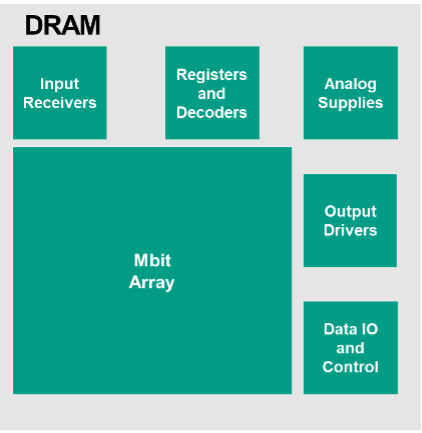
Schéma fonctionnel DRAM
Il existe de nombreux modes de défaillance sur la DRAM, qui peuvent être mappés à un nombre fini de modes de défaillance de niveau supérieur (TLFM) tels que vus par l’hôte. A titre d’exemple, il peut y avoir un défaut dans un décodeur d’adresse de ligne qui produit un mode de défaillance DRAM de « page de données corrompue ». Ce mode d’échec correspondrait à TLFM-03 Données corrompues : erreur multi-bits, comme indiqué dans le Tableau 1.
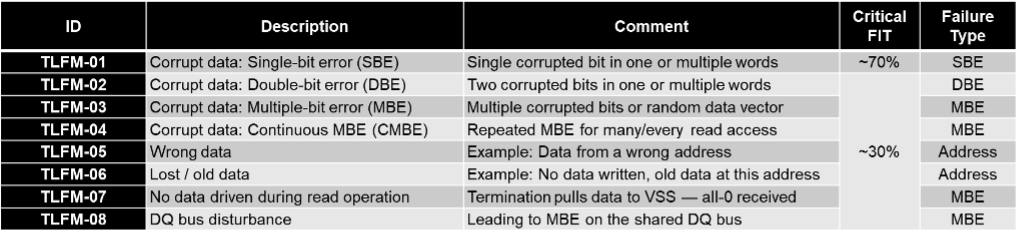
Modes de défaillance de niveau supérieur
Une brève description du TLFM est utile pour comprendre les impacts du système et comment atteindre la couverture de diagnostic nécessaire. TLFM-01 à TLFM-03 sont explicites, je vais donc me concentrer sur les cinq autres. TLFM-04 est une erreur répétée sur plusieurs bits (MBE) qui se produit à chaque cycle de lecture, quelle que soit l’adresse. Un exemple de ceci serait une broche d’E/S (DQ) ouverte sur le boîtier DRAM. TLFM-05 sont des données lues à partir de la mauvaise adresse.
Un exemple serait si le contrôleur émet une commande de lecture à l’adresse A et via un mode d’échec sur les données DRAM de l’adresse B est renvoyée à l’hôte. Ces types de modes de défaillance sont très difficiles à détecter car le mot de code ECC récupéré sera toujours valide. TLFM-06 est des données perdues ou anciennes. Cela se produit lorsqu’il y a un échec sur l’opération d’écriture sur un cycle précédent à la même adresse. Lors de la lecture ultérieure de l’adresse, il récupérera les « anciennes » données qui n’ont jamais été écrasées par l’échec d’écriture.
Encore une fois, cela est difficile à détecter car le mot de code ECC sera valide. TLFM-07 est une condition de non-entraînement lors d’une lecture. Dans le cas d’une DRAM Low-Power Double Data Rate 4/5 ou LPDDR4/5, le bus DQ est terminé bas et une condition d’absence de lecteur conduira à tous les zéros capturés par l’hôte. LPDDR est un type de mémoire à accès aléatoire dynamique synchrone à double débit qui consomme moins d’énergie et est destiné aux ordinateurs mobiles.
Cette condition peut ou non être un problème selon que la mise en œuvre de l’hôte ECC a ou non la condition tout à zéro comme mot de passe valide. Enfin, TLFM-08 est une perturbation sur le bus DQ qui corrompt les données lors de la transmission sur le lien physique. Cela se produit dans les systèmes à plusieurs rangs où les deux rangs partagent le bus DQ physique et la contention sur le bus en raison d’un défaut sur la mémoire provoque des données corrompues.
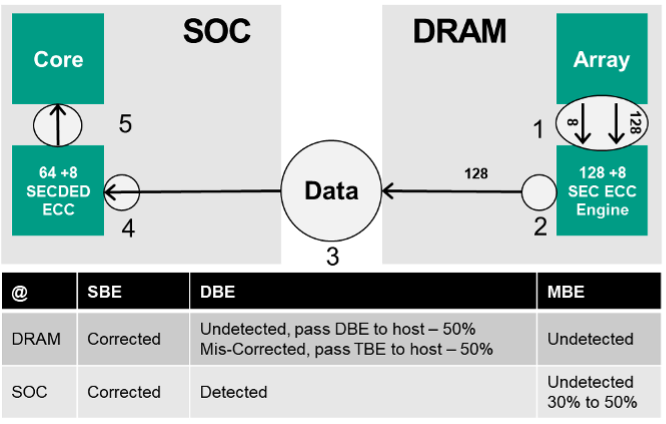
Discutons de l’approche traditionnelle de la couverture de diagnostic pour le sous-système DRAM dans les applications automobiles. La figure 3 montre un système sur puce (SoC) et un sous-système DRAM (dans ce cas LPDDR4). Lors d’un cycle de lecture, à un niveau d’octet (8 DQ), 128 bits de données et 8 bits de parité sont extraits de la matrice (1) et exécutés via le moteur SEC ECC intégré.
Les SBE sont détectés et corrigés et le paquet de données 128b est transmis à l’hôte (2). Il est important de noter que les corrections des bits individuels du tableau DRAM sont effectuées au niveau des E/S internes. La cellule qui stocke le mauvais bit n’est pas écrasée dans le cadre du processus de correction. Cela a des implications en ce qui concerne les failles latentes à deux points et affecte la métrique LFM illustrée à la figure 1.
Le SoC de cet exemple exécute une correction d’erreur simple 64 +8, une détection d’erreur double (SECDED) sur le chemin de données de bout en bout. SECDED est un code de Hamming étendu qui est populaire dans les systèmes de mémoire informatique. Ces 8 bits de parité sont écrits et lus comme toute autre donnée par la DRAM. Du côté hôte, les bits de données et de parité sont reconstruits en un mot de code ECC et évalués (4). 64 bits de données corrigées sont passés au cœur (5). Le tableau sous la figure décrit la couverture diagnostique globale de ce système. Comme vous pouvez le voir, cela offre une excellente couverture pour les erreurs sur un seul bit.
Les mots de données avec des erreurs sur deux bits (DBE) sont soit transmis à l’hôte sans être corrigés, soit, dans environ 50 % des cas, une erreur de correction se produit qui transforme le DBE en une erreur sur trois bits. Ceci est inhérent au moteur SEC ECC interne à la DRAM. L’effet de cette erreur est que le DBE de la DRAM est placé dans la colonne MBE de l’hôte, car il s’agit maintenant d’une erreur à trois bits. Selon la mise en œuvre de l’hôte SECDED, 30 à 50 % des erreurs de bits multiples ne seront pas détectées.
Système typique
Revenons maintenant au tableau 1. La plupart des FIT provenant de la DRAM résident dans TLFM-01 (erreurs sur un seul bit). La couverture diagnostique de ces erreurs est relativement simple. Mais il y a un pourcentage important du FIT critique total qui réside dans le seau d’erreurs sur plusieurs bits (TLFM-02 à TLFM-08). Certains d’entre eux peuvent être détectés avec des schémas SECDED d’usage courant, tandis que d’autres ne seront pas détectés. Avec l’approche traditionnelle illustrée à la figure 3, la quantité d’erreurs de bits multiples non détectées provenant de la DRAM empêche le système d’atteindre les métriques matérielles clés pour chaque ASIL illustré à la figure 1.
Où cela nous laisse-t-il ? De toute évidence, il existe des lacunes pour combler la solution de sécurité avec les approches traditionnelles. Heureusement, Micron a travaillé sur des produits qui résolvent ces problèmes au niveau de la DRAM et du système. Alors que la responsabilité d’évaluer et d’atteindre les objectifs de sécurité du système incombe à l’intégrateur, le fournisseur de mémoire peut aider à soutenir le processus.
En tant qu’intégrateur système axé sur la sécurité fonctionnelle, que devez-vous demander à votre fournisseur de mémoire ? Assurez-vous que les défauts de mémoire systématiques sont couverts par, idéalement, un processus certifié ISO 26262. Demandez l’analyse FMEDA effectuée sur le produit d’intérêt. Cette analyse doit inclure le package et les événements transitoires. Renseignez-vous sur les mécanismes de sécurité déployés sur la DRAM qui traitent les erreurs de bits multiples, les défauts latents à deux points et toute autre fonctionnalité permettant d’atteindre les métriques matérielles clés telles que définies par l’ASIL souhaité.
|
Micron

Aaron Boehm |
Ce sont des moments passionnants dans l’industrie automobile. Les progrès du matériel informatique transforment l’expérience de conduite en quelque chose qui ressemble à une scène d’un film de science-fiction. Aussi cool que cela soit, la sécurité fonctionnelle doit rester la priorité pour que ce mouvement se poursuive. C’est pourquoi les acteurs de l’industrie doivent rester concentrés sur la sécurité fonctionnelle de la mémoire et rendre possible des technologies sûres. Aujourd’hui, j’écris cet article dans mon bureau. Demain? Peut-être que je l’écris dans ma voiture en me rendant au travail pendant que le matériel conduit.