Comment les machines apprennent à devenir plus intelligentes
Découvrez les trois principales méthodes de formation pour les modèles d’apprentissage automatique.

Les développements récents de la technologie AI (intelligence artificielle) ont conduit à de nombreuses percées et à une croissance exponentielle pour les machines. La mesure dans laquelle le monde entier dépend désormais des machines ne connaît pas de limites. En fait, à ce stade, les solutions d’IA ne sont pas seulement une opportunité d’investissement clé pour les grandes entreprises, mais aussi un contributeur majeur à la résolution d’innombrables problèmes quotidiens dans nos vies.
Un sous-ensemble clé de l’IA est l’apprentissage automatique, souvent simplement appelé ML. Ce n’est que grâce au travail inestimable que les chercheurs et les scientifiques ont investi dans les fondations du ML que nous sommes désormais capables de récolter des performances maximales à partir de technologies basées sur l’IA hautement compétentes.
Dans cet article, nous parlerons de la façon dont, au fil des ans, les humains ont créé des machines capables d’intelligence, c’est-à-dire la capacité d’imiter le processus de pensée humaine et de prendre des décisions basées sur des expériences.
Sommaire
Qu’est-ce que l’apprentissage automatique ?
Avant de parler des différentes méthodologies à l’aide desquelles les humains apprennent aux machines à se comporter comme des humains, passons en revue la définition de base de l’apprentissage automatique.
L’apprentissage automatique est la méthode par laquelle les humains apprennent aux machines à apprendre à partir d’un ensemble de données historiques et leur permettent d’effectuer certaines actions à l’avenir en fonction de leur apprentissage passé. L’apprentissage automatique est une combinaison de beaucoup de choses, des algorithmes informatiques et de l’analyse de données aux mathématiques et aux statistiques. C’est la technologie sur laquelle repose fortement la construction de systèmes artificiellement intelligents.
Comment les machines sont-elles entraînées ?
Le processus consistant à faire en sorte que les machines apprennent à partir de données historiques est connu sous le nom de formation.
La science de l’apprentissage automatique s’articule autour de l’enseignement de la machine en utilisant des ensembles de données de différentes tailles composés de faits et/ou de chiffres utiles ou aléatoires et en les transmettant à la machine. L’essence de cette activité est d’aider la machine à observer les données, à établir des connexions significatives entre les différentes informations fournies et à se préparer à prendre des décisions concernant les données entrantes en incorporant ces connexions préétablies, également appelées règles.
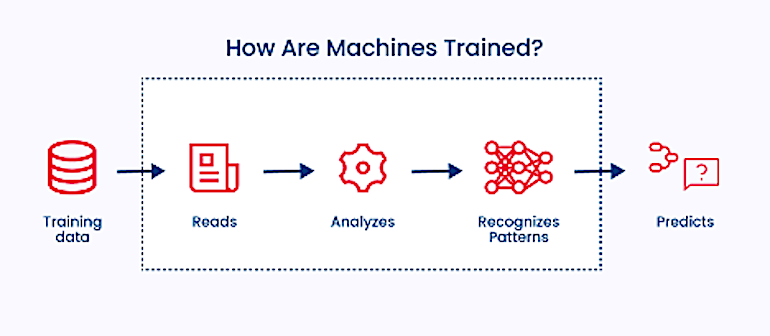
Les modèles d’apprentissage automatique suivent souvent une ou plusieurs des méthodes de formation principales suivantes.
- Enseignement supervisé
- Apprentissage non supervisé
- Apprentissage par renforcement
Pour la formation initiale, nous utilisons un ensemble de données où l’entrée et/ou la sortie attendue peuvent ou non être clairement définies. Le processus de formation utilise des données de formation. Une fois que la machine a été entraînée, elle reçoit des données de test pour savoir si la machine a appris ou non à partir de l’ensemble de données d’entraînement.
Passons en revue chacune de ces méthodes de formation un peu plus en détail et explorons comment elles sont utilisées pour rendre les machines plus intelligentes.
Enseignement supervisé
Ce type d’algorithme d’apprentissage automatique utilise un ensemble de données contenant des données étiquetées. Cela signifie que vous dites à la machine ce qu’est chaque article. De cette façon, nous pouvons théoriquement prédéfinir les règles et tout ce que la machine a à faire est d’étudier les mappages existants et d’apprendre ces règles.
Nous pouvons en outre diviser les algorithmes d’apprentissage supervisé en deux sous-types, la classification et la régression.
Classification: Cette méthode est utilisée lorsque la machine doit être entraînée à répondre en termes binaires, tels que oui-non, bon-mauvais ou vrai-faux. Les données d’entraînement sont constituées d’éléments qui ont déjà été classés en différentes catégories. Pour chaque catégorie, la machine étudie chaque élément de près et identifie les caractéristiques communes à tous les éléments de cette catégorie. Cela permet à la machine d’établir des relations entre les éléments et leurs catégories respectives. Il utilise ces règles pour identifier les éléments dans les données de test et les classer correctement.
Régression: Le modèle de régression est utilisé lorsque vous avez besoin de prévisions en termes de valeurs numériques, telles que les prix des logements ou les températures. L’ensemble de données d’apprentissage contient plusieurs variables ainsi que des sorties qui peuvent ou non dépendre desdites variables. La machine étudie les variables d’entrée et détermine comment, le cas échéant, chaque variable affecte la valeur de la sortie, conduisant à la reconnaissance de formes ou au développement de règles. Pour les données de test, la machine utilise ces règles pour calculer une estimation ou une valeur prédite pour la sortie.
Apprentissage non supervisé
La principale différence entre l’apprentissage supervisé et non supervisé est que les éléments ne sont pas étiquetés dans l’ensemble de données utilisé pour ce dernier. Prenons un exemple pour mieux le démontrer.
Supposons que vous souhaitiez qu’une machine puisse classer les éléments d’un ensemble de données contenant des images de différents types d’outils de jardinage, tels que des truelles, des pelles, des râteaux et des bêches.
Dans le cadre de l’apprentissage supervisé, vos données d’entraînement contiendraient des images avec leurs identifiants. Par exemple, si vous saisissez l’image d’un pique, vous indiquerez à la machine qu’il s’agit d’un pique. La machine étudiera alors toutes les pelles et leurs caractéristiques communes pour apprendre à identifier une pelle dans le futur.
Cependant, si vous utilisez le modèle d’apprentissage non supervisé, vous saisirez des images de toutes sortes d’outils de jardinage sans les étiqueter. Par exemple, si vous saisissez l’image d’un chat, vous ne direz pas à la machine qu’il s’agit d’un chat. La machine devra déterminer par elle-même comment chaque image peut (ou non) être liée à celles qui la précèdent, puis regrouper des images similaires dans une catégorie. Ainsi, la machine apprend à former des catégories par elle-même sans qu’on lui dise explicitement quelles sont les catégories. Ce type de modèle de formation fonctionne bien pour les ensembles de données où les structures ou les modèles peuvent ne pas être apparents pour l’humain moyen.
Apprentissage par renforcement
La troisième méthode importante est basée sur le concept de renforcement, que certains d’entre vous connaissent peut-être si vous avez déjà suivi un cours de psychologie 101. Si vous avez déjà essayé d’apprendre à votre chien des trucs sympas en le motivant avec des friandises, vous avez utilisé le système de récompense.
Contrairement aux deux premières méthodes, ce modèle s’appuie fortement sur la rétroaction. Pour chaque décision prise par la machine, vous indiquez à la machine la sortie correcte afin qu’elle puisse déterminer si elle a fait une bonne ou une mauvaise prédiction. Grâce à des essais et erreurs répétés, la machine devient de plus en plus précise.
Un exemple simple et concret d’apprentissage par renforcement peut être vu dans l’affichage des publicités en ligne. La machine peut déterminer quelles publicités ont le plus de succès et valent la peine d’être diffusées en fonction du nombre de personnes qui cliquent dessus. Si la machine obtient plus de clics (récompense plus élevée) sur une certaine annonce d’un groupe cible particulier, elle saura que la décision d’afficher cette annonce à ce groupe était bonne.
Dernières pensées
Alors que certains semblent déterminés à tenter de régler une fois pour toutes le débat humains contre machines, d’autres estiment que ce type de comparaison est futile. Il n’en reste pas moins que l’être humain est venu en premier, et la machine a suivi. Tant que notre passion pour la croissance et notre besoin de perfection seront vivants, les algorithmes d’apprentissage automatique continueront de s’améliorer et deviendront de plus en plus précis, nous aidant à atteindre des taux de réussite et de précision apparemment impossibles.